sklearn random forest regressor
There are 2 ways to combine decision trees to make better decisions. One easy way in which to reduce overfitting is Read More Introduction to Random Forests in.
 |
| Random Forest Regression Random Forest Regression Is A By Chaya Bakshi Level Up Coding |
It is widely used for classification and regression predictive modeling problems with structured tabular data sets eg.
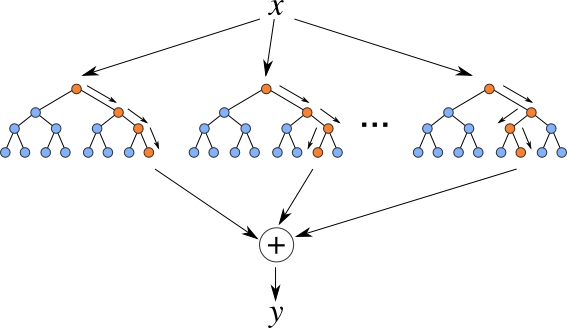
. The default mse loss function is not suited to this problem. Random Forest is a popular and effective ensemble machine learning algorithm. However they can also be prone to overfitting resulting in performance on new data. Steps to perform the random forest regression.
Is there a way to define a custom loss function and pass it to the random forest regressor in Python Sklearn etc. Random Forest Classifier in Sklearn. The feature importance variable importance describes which features are relevant. Note that this implementation is rather slow for large datasets.
Print Parameters currently in usen. Random Forest is a supervised machine learning model used for classification regression and all so other tasks using decision trees. Integration of Completely Random Trees Ensemble. We can easily create a random forest classifier in sklearn with the help of RandomForestClassifier function of sklearnensemble module.
Data as it looks in a spreadsheet or database table. The following are the basic steps involved in performing the random forest algorithm. In our experience random forests do remarkably well with very little tuning required. A random forest regressor providing quantile estimates.
From sklearnensemble import RandomForestRegressor rf RandomForestRegressor random_state 42 from pprint import pprint Look at parameters used by our current forest. Random Forest Regression An effective Predictive Analysis. To look at the available hyperparameters we can create a random forest and examine the default values. Averaging Bootstrap Aggregation - Bagging Random Forests - Idea is that we create many individual estimators and average predictions of these estimators to make the final predictions.
I want to build a Random Forest Regressor to model count data Poisson distribution. Soft votingmajority rule classification for inappropriate estimators. Above 10000 samples it is recommended to use func. Random Forest Regressor and Parameters Python Housing price in Beijing Private Datasource Random Forest Regressor and Parameters.
Random Forest is an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation commonly known as bagging. We pointed out some of the benefits of random forest models as well as some potential drawbacks. This Notebook has been released under the Apache 20 open source license. In the following code we will import the dataset from sklearn and create a random forest classifier.
Try it and see. Random Forest produces a set of decision trees that randomly select the subset of the training set. Step By Step Implementation. Pick N random records from the dataset.
Some of the import. Def randomForestRegressorStudyXY setSize comment. In this article weve demonstrated some of the fundamentals behind random forest models and more specifically how to apply sklearns random forest regressor algorithm. This tutorial demonstrates a step-by-step on how to use the Sklearn Python Random Forest package to create a regression model.
Is there any implementation to fit count data in Python in any packages. Random Forest Hyperparameters Sklearn Hyperparameters are used to tune in the model to increase its predictive power or to make it run faster. Random forest is known to work well or even best on a wide range of classification and regression problems. You can vote up the ones you like or vote down the ones you dont like and go to the original project or source file by following the links above each example.
History Version 7 of 7. This is a four step process and our steps are as follows. Build a decision tree based on these N records. It is really convenient to use Random Forest models from the sklearn library Always tune Random Forest models.
Pick a random K data points from the training set. Most accurate most interpretable and the like. Random Forest Regressor should not be used if the problem requires identifying any sort of trend. Random_state int RandomState instance or None.
Fitting Random Forest Regression to the Training set from sklearnensemble import RandomForestRegressor regressor RandomForestRegressorn_estimators 50 random_state. In case of a regression problem for a new record each tree in the forest predicts a value. Random Forest Regression Ensemble. Runs random forest regressor on the data to see the performance of the prediction and to determine predictive features X_trainXsetSize X_testXsetSize Y_trainYsetSize Y_testYsetSize rf_regRandomForestRegressorn_estimators10 rf_regfitX_train Y_train.
Decision trees can be incredibly helpful and intuitive ways to classify data. From sklearnensemble import RandomForestRegressor from sklearndatasets import make_regression X y make_regressionn_features4 n_informative2 random_state0 shuffleFalse. The stochastic forests in sklearn s mean the return probability of predict_proba corresponding to each sample and get. Random Forest Regression is a bagging technique in which multiple decision trees are run in parallel without interacting with each other.
The following are 30 code examples of sklearnensembleRandomForestRegressorThese examples are extracted from open source projects. It can help with better understanding of the solved problem and sometimes lead to model improvements by employing the feature selection. Choose the number N tree of trees you want to build and repeat steps 1 and 2. The authors make grand claims about the success of random forests.
This idea is generally referred to as ensemble learning in the machine learning community. For a new data point make each one of your Ntree. In this tutorial youll learn what random forests in Scikit-Learn are and how they can be used to classify data. Build the decision tree associated to these K data points.
Random Forest Regressor should be used if the data has a non-linear trend and extrapolation outside the training data is not important. Random forest regressor sklearn. Random Forest can also be used for time series forecasting although it requires that the time series dataset be transformed into a. The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on.
Choose the number of trees you want in your algorithm and repeat steps 1 and 2. Thank you for taking the time to read this article. In this post I will present 3 ways with code examples how to compute feature importance for the Random Forest algorithm from scikit.
 |
| Random Forest Regression Random Forest Regression Is A By Chaya Bakshi Level Up Coding |
 |
| Sklearn Random Forest Tutorial Cheap Sale 56 Off Www Ingeniovirtual Com |
 |
| Random Forest Regression In Python Geeksforgeeks |
 |
| Random Forest Regression In 5 Steps With Python By Samet Girgin Pursuitdata Medium |
 |
| Random Forest Regression In Python Geeksforgeeks |

Posting Komentar untuk "sklearn random forest regressor"